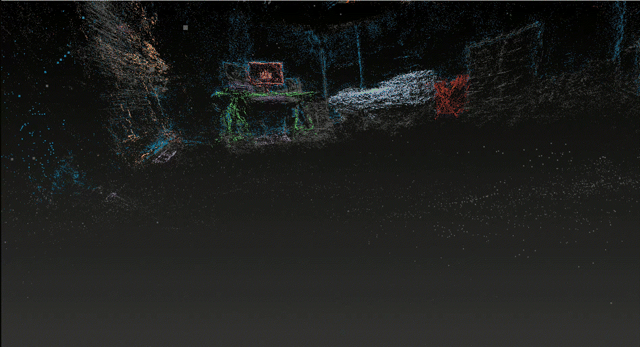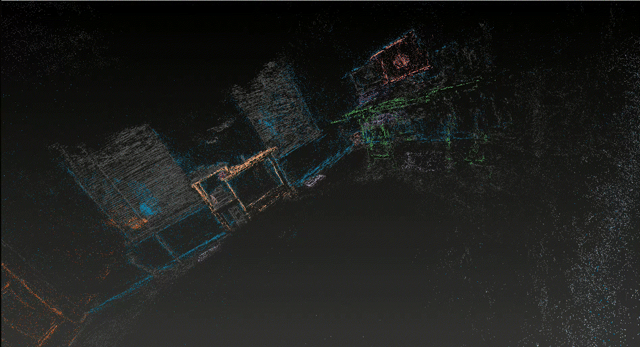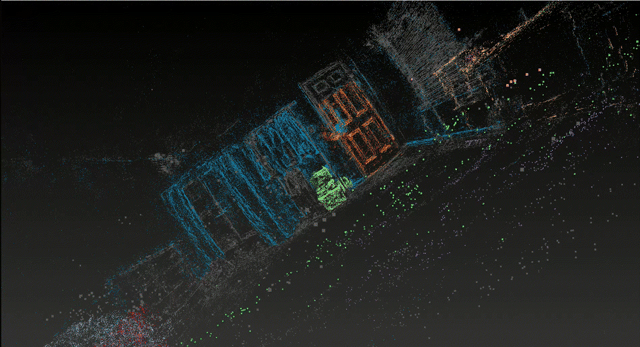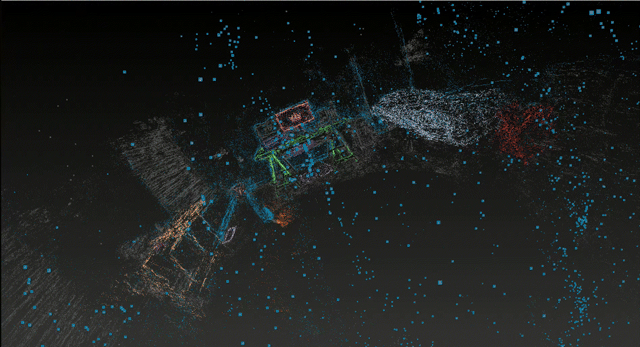Overview
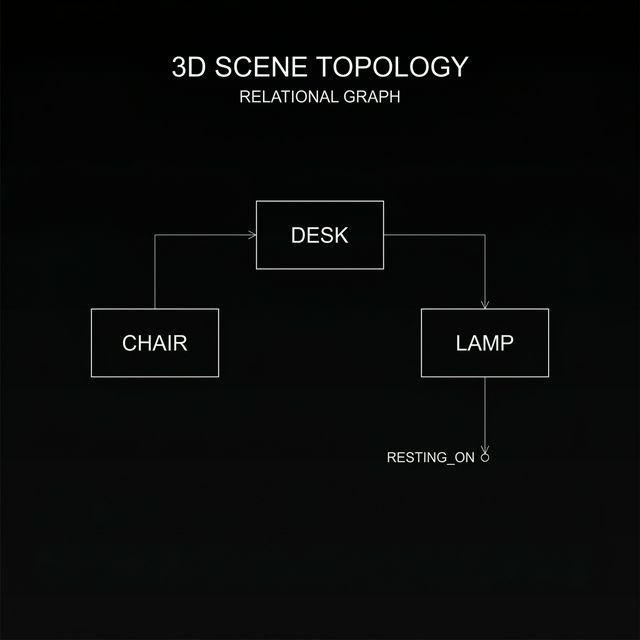
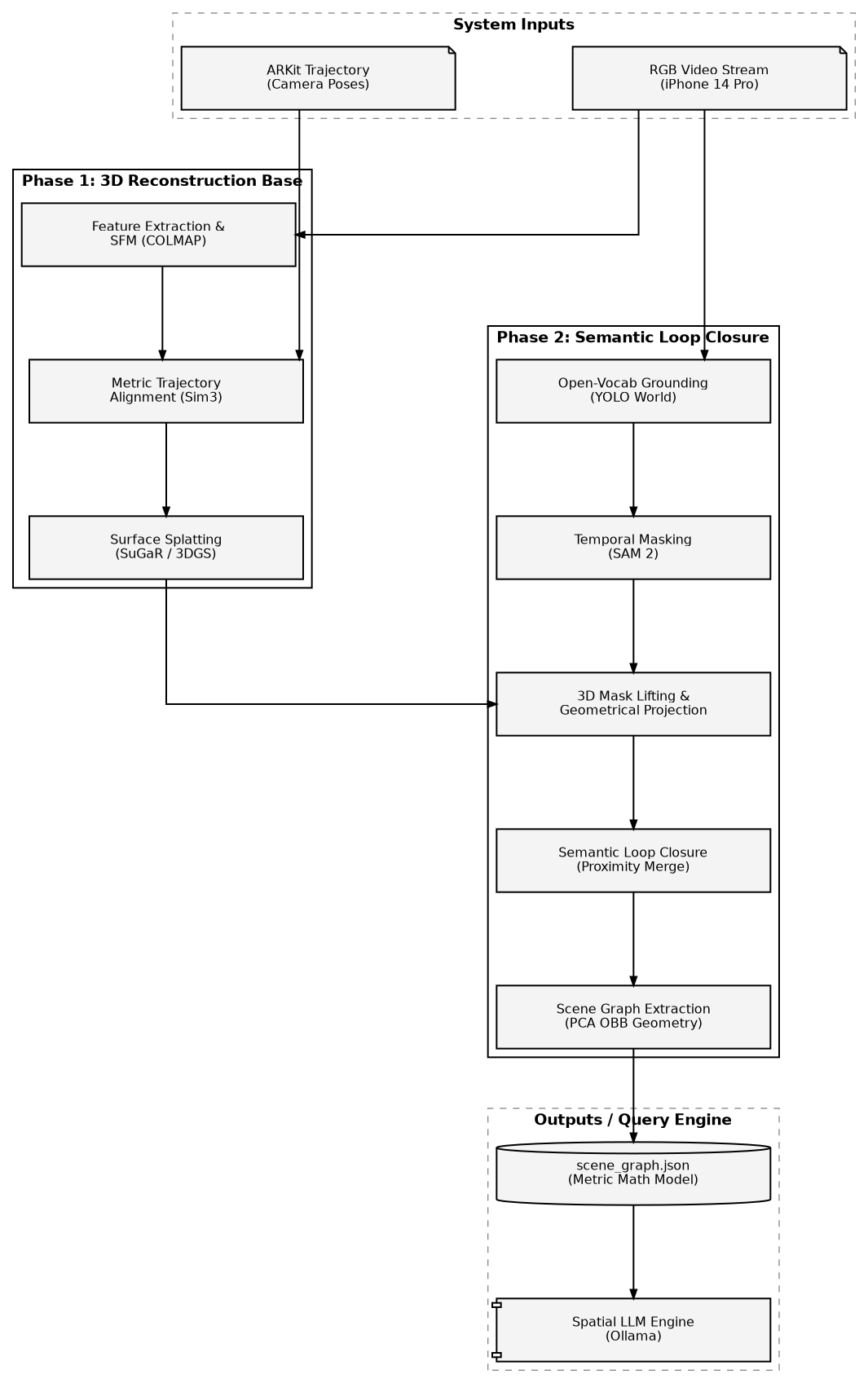
This project presents a proof-of-concept system that extracts metric-scale semantic scene graphs from RGB+IMU video on consumer hardware. Unlike existing approaches (ConceptGraphs, HOV-SG) that require RGB-D sensors and high-end GPUs, this system achieves spatial relationship understanding from monocular RGB with inertial sensor data on an 8GB laptop GPU.
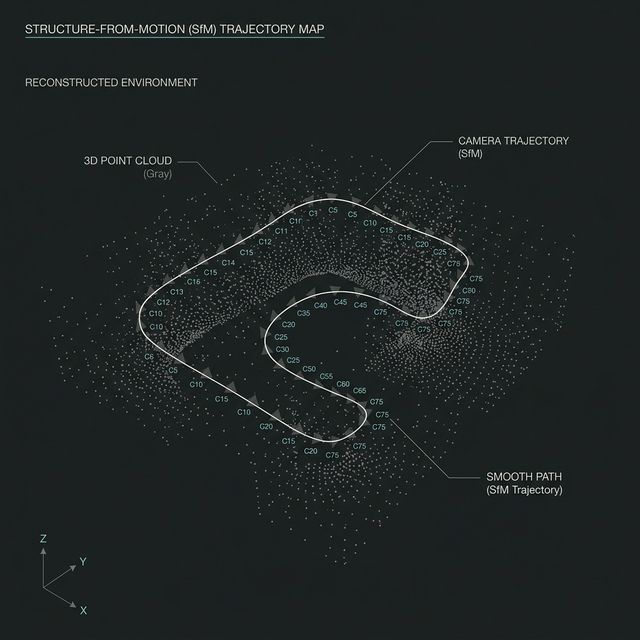
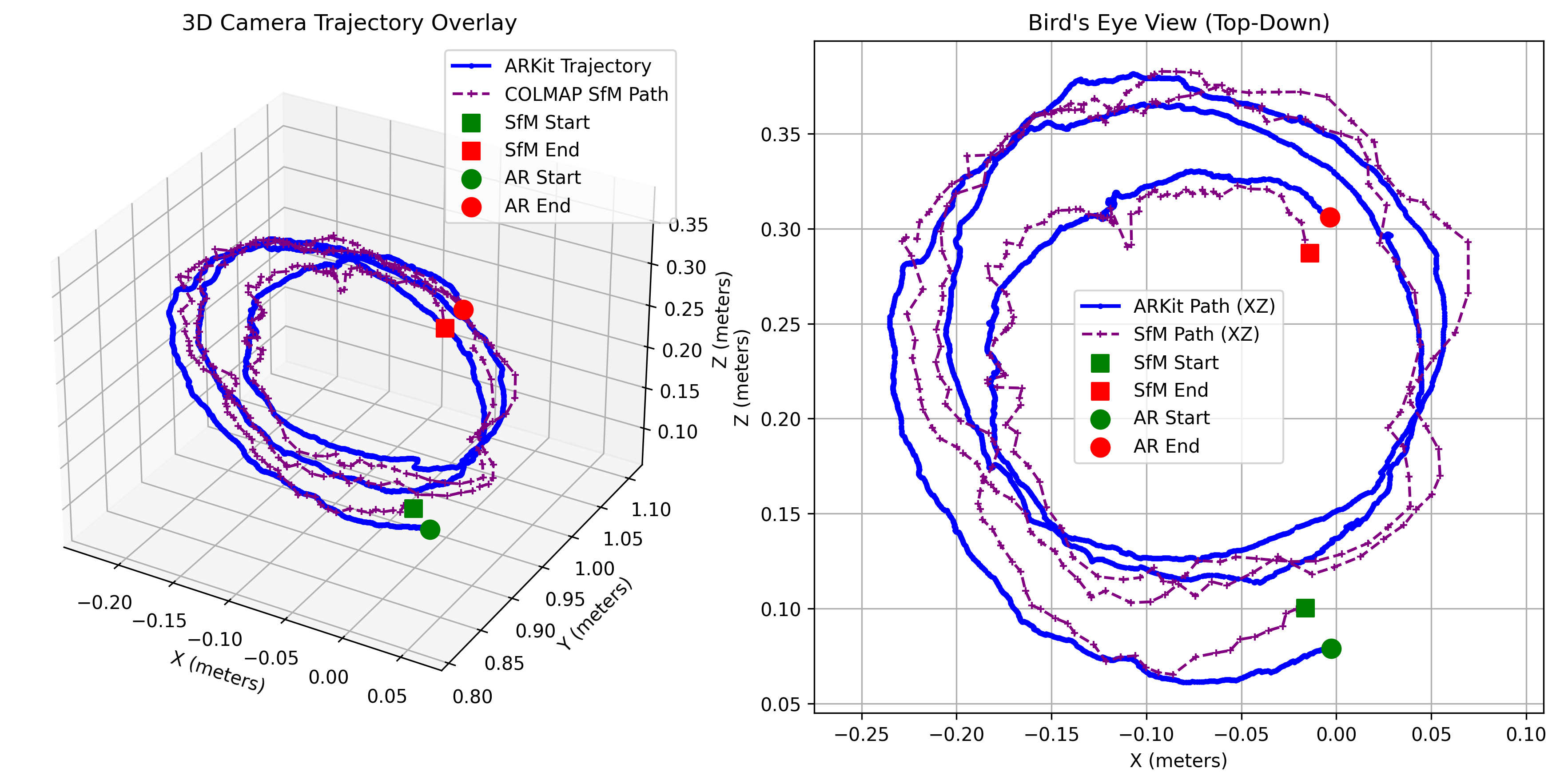
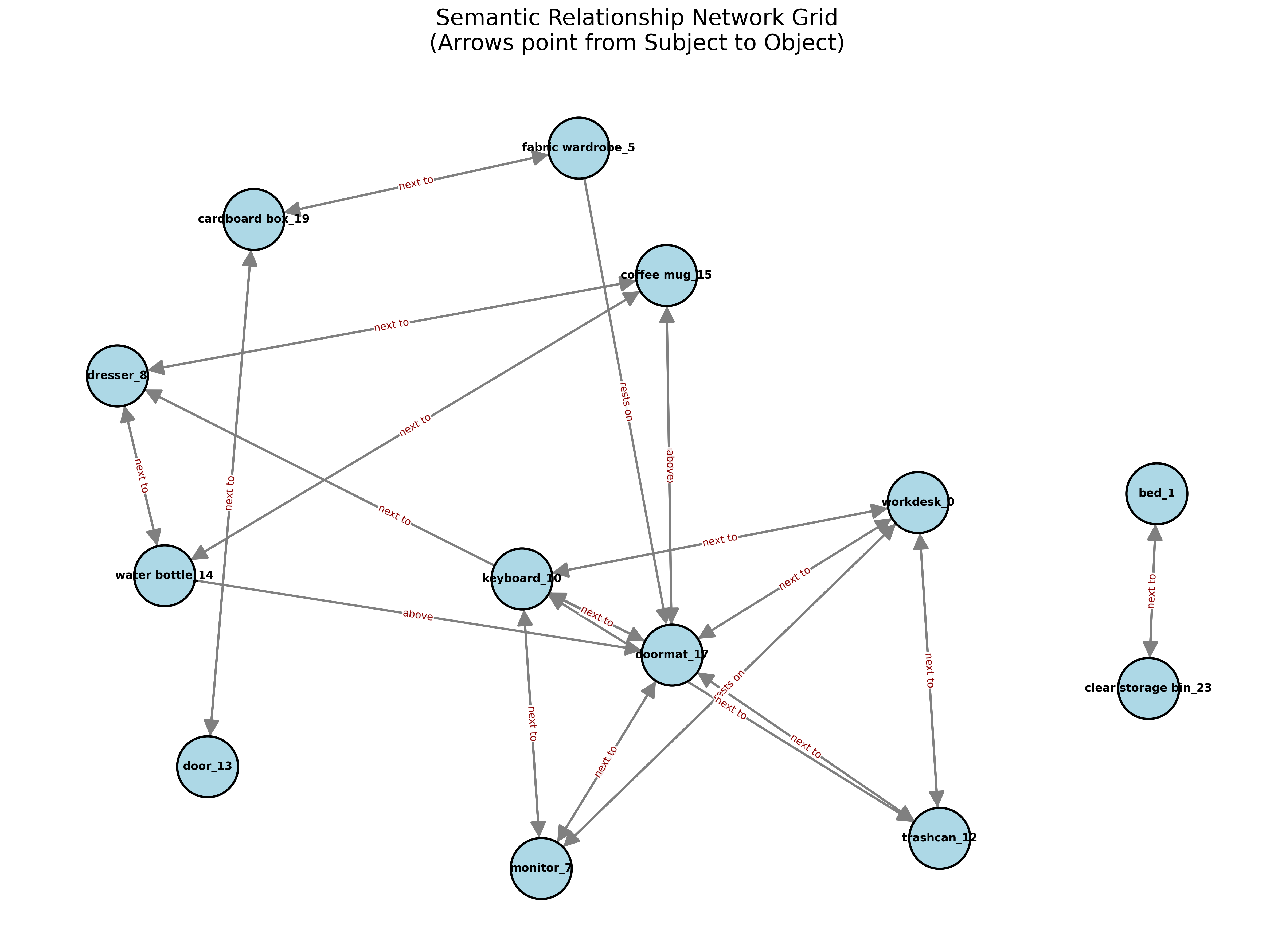
The system combines 3D Gaussian Splatting (SuGaR) for dense surface reconstruction, open-vocabulary detection (YOLO World + SAM 2) for semantic understanding, and ARKit IMU alignment for metric scale recovery. By using monocular RGB with inertial sensors instead of depth sensors, this unique combination enables scene graph extraction on consumer hardware, though at the cost of dimensional precision.
⚠️ Evaluation Scope: This work presents single-scene validation on a representative bedroom environment. All reported metrics are specific to this scene and may not generalize. While single-scene evaluation limits generalization claims, these results establish feasibility and identify key accessibility-precision tradeoffs for future multi-scene investigation.